\[Paper Review\] Meshed-memory transformer for image captioning
논문 간단 소개
- image captioning task에서 transformer 모델을 활용한 모델 중 가장
Abstract
- image encoding
- 학습된 사전 지식(caption)을 기반으로 image region간의 multi-level representation을 학습
- language generation
- low-level과 high-level feature를 모두 활용하는 mesh-like connectivity 활용
- $M^2$ Transformer
- 다른 fully-attentive model과 비교해서 성능을 비교하고,
- COCO image-text set에서 sota 기록
Introduction
- RNN + attention, Transformer, Bert 등 다양하게 이용되어 왔음
- multimodal task는 기존 unimodal task와 다른 구조를 띠어야 함
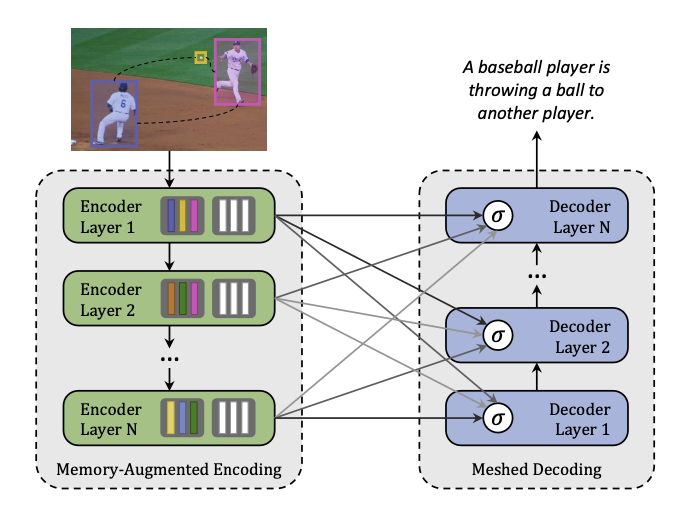
encoding
MemoryAugmentedEncoding- 이미지 구역 및 그 사이 관계가 multi-level(low-level, high-level) 로 인코딩됨
- memory vector를 사용하여 사전지식을 encoding 및 관계를 모델링함
decoding
MeshedDecoding- 학습된 gated mechanism으로 달성되는데, 각 단계별로 multi-level 의 기여도를 weight화함
→ encoder 와 decoder 간에 meshed connectivity 로 구조화됨
Structure
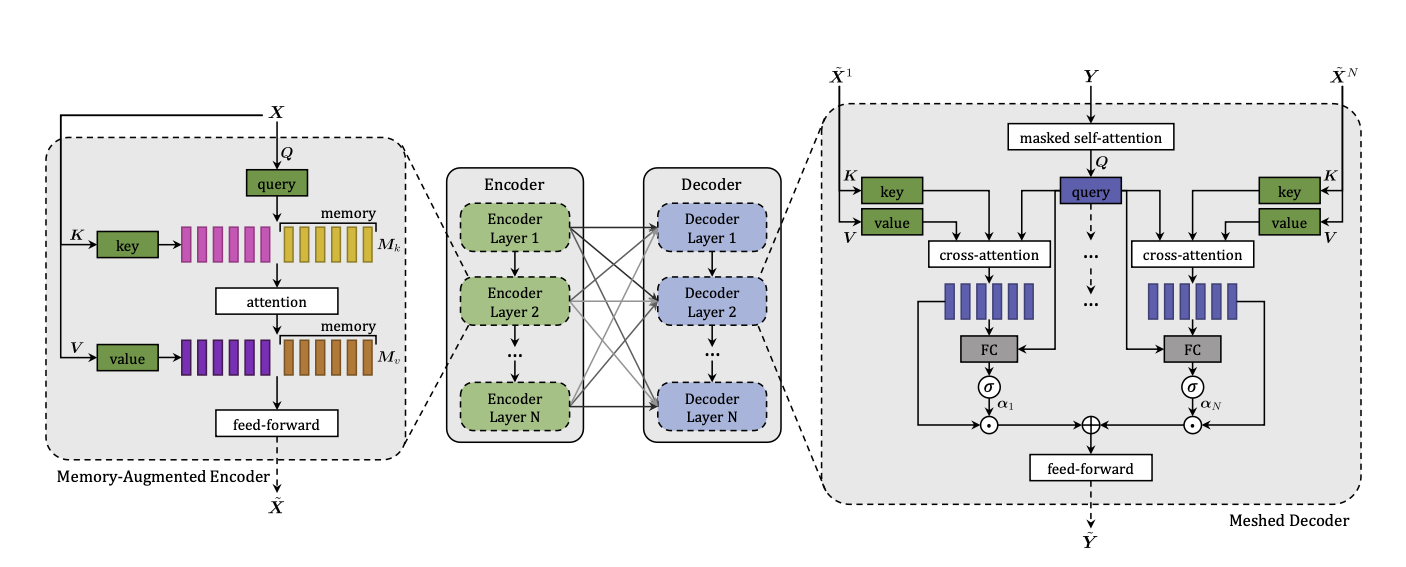
Encoding
-
input image로부터 추출된 image region X (집합)
- 현재 image detection dataset을 활용하지만, 마디별 note 및 chord 범위로 설정 예정
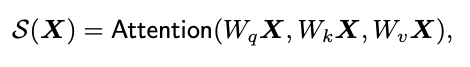
- learnable weights W(q,k,v 에 대응되는)
- S(X) = X의 weighted sum of values
- image feature(region) 간의 pairwise similarity
- 하지만 이러한 방식의 self-attention은 사전 지식( a priori knowlendge)를 반영하지 못함
ex) 사람과 농구공이 있으면 player나 game과 같은 정보를 추론해내기 어려움
1. Memory-Augmented Attention
memory로 data augmentation이 진행되었다.
- key 또는 value가 slot의 형태로 확장되고, 이는 사전지식을 encoding할 수 있음
- 이러한 slot은 learnable vector로서 SGD로 업데이트 가능(parameter)
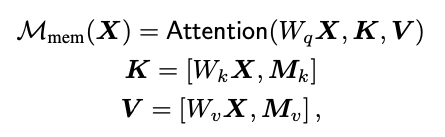
- $M_k, M_v$ 는 $n_m$ 개의 row수를 가진 학습가능한 matrix
- , 는 concatenation을 의미
- 위 learnable parameter에 의해 X에 embedded 되지 않은 정보를 학습 가능
2. Encoding layer
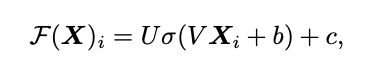
- 이후 Memory augmented attention이 Position-Wise FFL 에 적용
- 2개의 affine transformation으로 이루어짐(non-linearity는 한곳에만 적용)
3. Residual Connection + layer norm
각각의 sub-component(Memory-augmented attention 과 Encoding Layer)가 위 방식으로 감싸짐
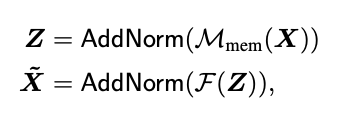
AddNorm은 Residual Connection + Layer Normalization
4. Full encoder
- 여러 layer, 이전 레이어 아웃풋이 다음 레이어 인풋으로 들어감
- 더 높은 encoding layer는 이전에 이미 인식된 관계 정보를 사용할 수 있음
- 다양한 수준의 output을 생성
Decoding
3.2 Meshed Decoder
- 이전 step의 생성된 word와 region encoding
- multi-layer structure
meshed Cross attention
- transformer의 cross-attention과 달리, 모든 encoding layer를 활용하여 생성 가능
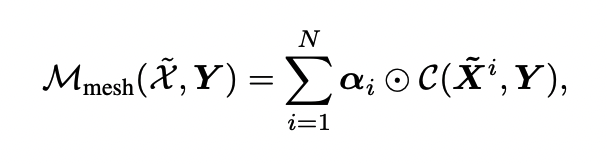 $C$ : encoder-decoder cross attention
$C$ : encoder-decoder cross attention
- decoder 로부터의 query와, encoder로부터의 key-value 쌍의 cross attention
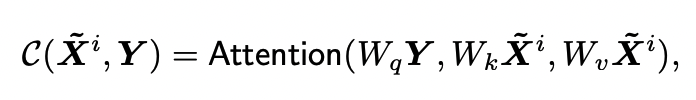
$\alpha_i$ : cross-attention 결과와 같은 크기의 weight matrix
- 각 encoding layer의 기여도 및 상대적인 중요도를 조절해주는 값
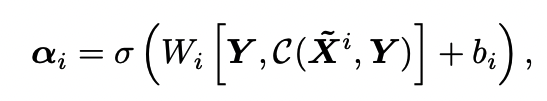
- input query와 Cross Attention output간의 관련성 측정한 결과값
- $W_i$ 는 2d*d matrix
Masked Self attention
$S_mask$
- input sequence Y의 t번째 element로부터의 query
- 왼쪽의 subsequence로부터 얻은 key와 value
FFW + AddNorm
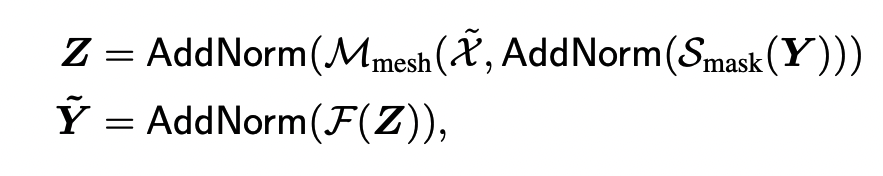
- 여러 layer로 stack
- 결과적으로 t 번째 element에 기반하여 t+1 번째 시점이 예측됨
Training
- XE(word-level Crossentropy loss)로 pre-training
-
Ground-truth word를 기반으로 다음 token을 예측
-
- Reinforcement learning 활용한 예측
- self-critical sequence training approach
- topk
Dataset : COCO
- 120,000 image with 5 captions each
- nocap : 15,100 images annotated with 11 human-generated captions
Reference
- From artificial neural networks to deep learning for music generation: history, concepts and trends
- https://towardsdatascience.com/generating-music-with-artificial-intelligence-9ce3c9eef806
- https://topten.ai/music-generators-review/
