(Paper Review) AudioLM ; a language Modeling Approach to Audio Generation
논문 간단 소개
Google Research 에서 개발한 모델. Semantic 과 acuostic, 두 갈래의 tokenization으로 나누어 성능 향샹을 이룸
- Transcript(대본)을 통한 audio generation process가 주를 이루어왔음
- speech synthesis에서 텍스트 대본
- 피아노에서 midi Representation
- 하지만 transcript가 없는 상황에서는 생성에 어려움을 겪음
- speech voice recover : speaker characteristic 이 필요함
AuodioLM의 허들
- 대규모 말뭉치를 학습한 language model들은 최근 좋은 성능을 보임
- AudioLM은 그러한 진보에 박차를 가하여(그 구조를 따와서) annotated data 없이 audio를 생성할 수 있음
- 하지만 language model로부터 audio language model로 가려면 허들이 존재함
- audio 생성을 위해서는 language 생성보다 더 밀도있는 데이터가 필요함
- text와 audio는 one-to-many 관계에 있어서, 같은 문장도 speaker, 감정, 스타일에 따라 달라짐
이러한 허들을 극복하기 위하여
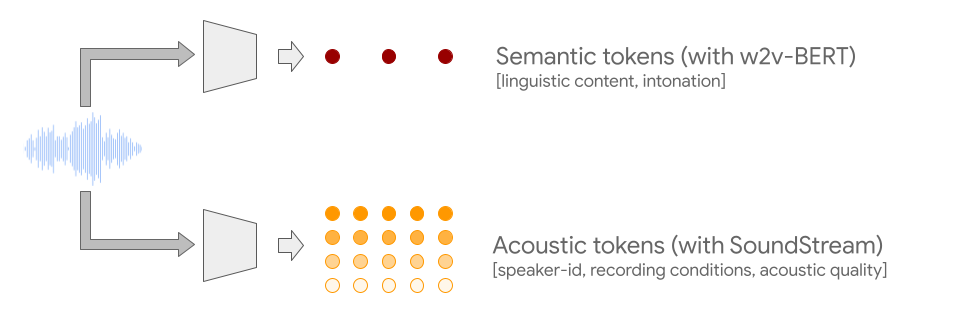
- semantic token (from W2v-BERT)
- local dependency(speech의 음소, 음악의 melody)
- global long-term structure(speech의 맥락, 음악의 harmony나 rhythm)
- 긴 sequence를 허락하기 위하여 audio signal을 downsampling함
- acoustic token (from SoundStream neural codec)
Audio-Only language model
- AudioLM은 audio data만을 학습(text나 symbolic representation을 학습하지 않음)
- Hierachical한 모델(high level-> low level)
- semantic token -> coarse acoustic token -> fine acoustic token으로 chainin하는 구조
- chain 사이사이에 transformer 모델이 활용됨
1. Semantic token

- language model과 같이 next token을 예측하는 구조
2. coarse acoustic token

- Genrerated token 과 poast coarse acoustic token을 concat함
- 이러한 형태로 acoustic token이 예측됨
- 이 단계에서 speaker의 특성(음색 등)이 모델링됨
3. fine acoustic token
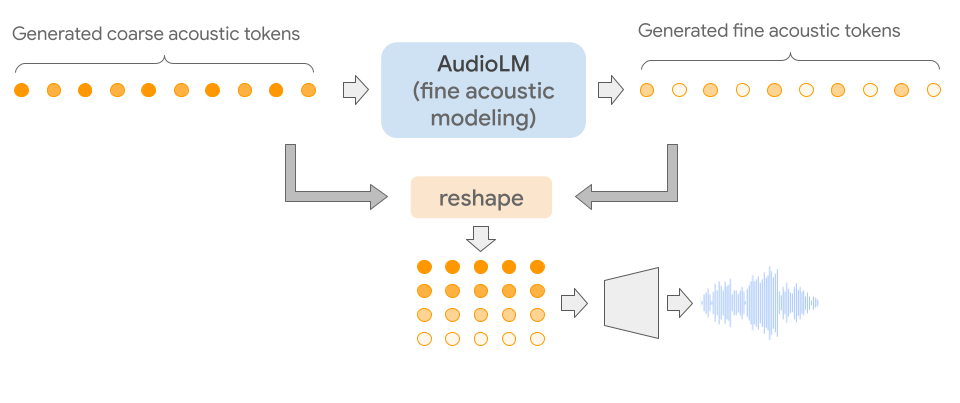
- 최종 audio에 detail을 추가함
- 최종 acoustic token을 Soundstream decoder를 통해 reconstruct
결론적으로
- piano continumation ,speech continuation, unconditional generation 등의 task에서 좋은 성능을 냄
- 이 페이지에서 디테일한 확인이 가능
Reference
- https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html
